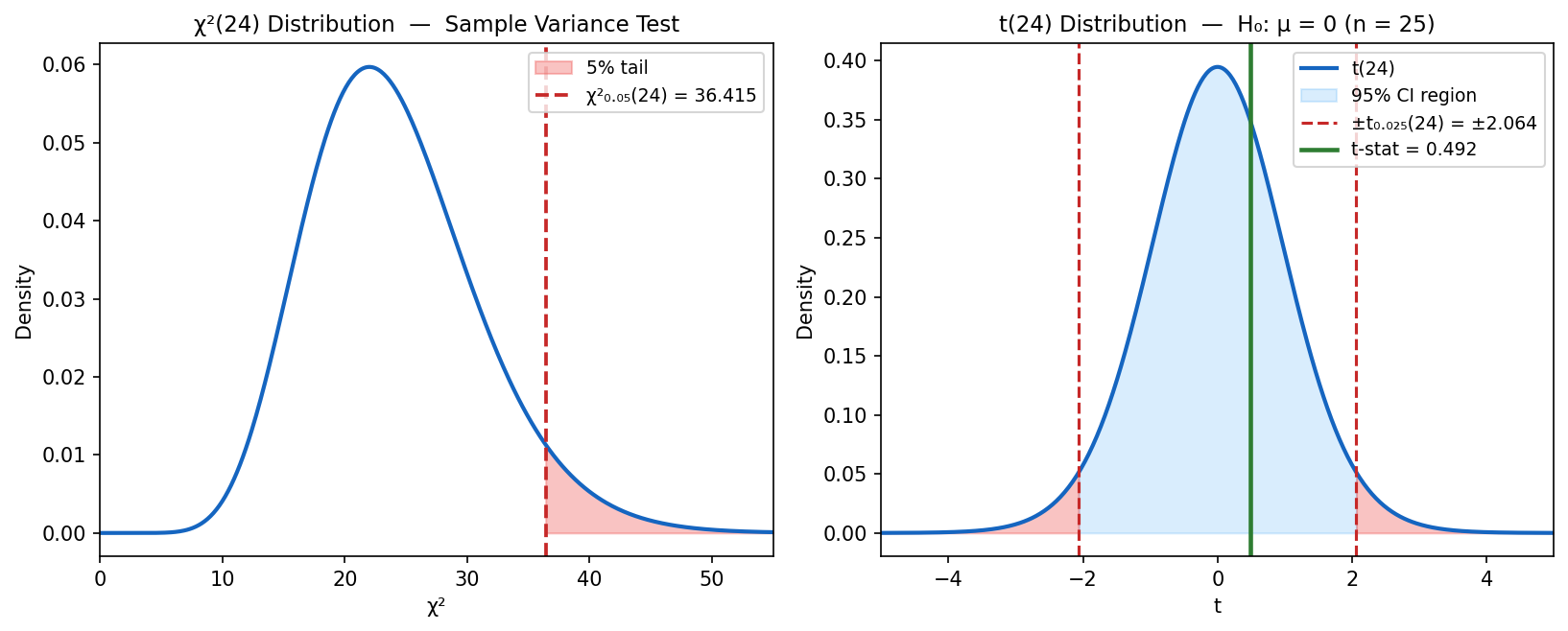
zt_tpdf = (x, v) => {
const c = gamma_func((v+1)/2) / (Math.sqrt(v * Math.PI) * gamma_func(v/2));
return c * Math.pow(1 + x*x/v, -(v+1)/2);
}
zt_main_curve = Array.from({length: 401}, (_, i) => {
const x = -5 + (i / 400) * 10;
return { x, y: zt_tpdf(x, nu_val) };
})
zt_z_line = Array.from({length: 401}, (_, i) => {
const x = -5 + (i / 400) * 10;
return { x, y: Math.exp(-x*x/2) / Math.sqrt(2 * Math.PI) };
})
zt_left_tail = Array.from({length: 101}, (_, i) => {
const x = -5 + (i / 100) * 3.04;
return { x, y: zt_tpdf(x, nu_val) };
})
zt_right_tail = Array.from({length: 101}, (_, i) => {
const x = 1.96 + (i / 100) * 3.04;
return { x, y: zt_tpdf(x, nu_val) };
})
zt_compare_curves = {
if (zt_overlay_opt === "None") return [];
return [3, 10, 30].flatMap(v =>
Array.from({length: 401}, (_, i) => ({
x: -5 + (i / 400) * 10,
y: zt_tpdf(-5 + (i / 400) * 10, v),
label: `t(${v})`
}))
);
}
{
const ymax = Math.max(...zt_main_curve.map(d => d.y)) * 1.15;
return Plot.plot({
width: 680,
height: 420,
marginLeft: 55,
marginBottom: 45,
marginTop: 35,
x: { label: "x", domain: [-5, 5] },
y: { label: "Density", domain: [0, ymax] },
color: { legend: zt_overlay_opt !== "None" },
title: `t(ν = ${nu_val}) vs N(0,1) • Shaded: tail area |x| > 1.96`,
marks: [
Plot.areaY(zt_left_tail, { x: "x", y: "y", fill: "steelblue", fillOpacity: 0.25 }),
Plot.areaY(zt_right_tail, { x: "x", y: "y", fill: "steelblue", fillOpacity: 0.25 }),
zt_compare_curves.length > 0
? Plot.line(zt_compare_curves, { x: "x", y: "y", stroke: "label", strokeWidth: 1.5, strokeDasharray: "4,2", opacity: 0.75 })
: null,
Plot.line(zt_z_line, { x: "x", y: "y", stroke: "crimson", strokeWidth: 2, strokeDasharray: "6,4" }),
Plot.line(zt_main_curve, { x: "x", y: "y", stroke: "steelblue", strokeWidth: 2.5 }),
Plot.ruleX([-1.96, 1.96], { stroke: "#aaa", strokeDasharray: "3,2" }),
Plot.ruleY([0], { stroke: "#e0e0e0" })
].filter(Boolean)
});
}