Problem 1 (Large-Sample CI): A random sample of \(n = 200\) bond funds yields mean annual return \(\bar{y} = 6.8\%\) with \(s = 4.2\%\). Construct (a) a 90% CI and (b) a 99% CI for the true mean return. Compare and interpret. (Wackerly §8.6)
Problem 2 (Sample Size): You want to estimate the proportion of Azerbaijani broadband subscribers experiencing peak-hour speeds below 50% of their plan, to within 0.02 with 95% confidence. (a) If \(p \approx 0.35\), find \(n\). (b) Find \(n\) if \(p\) is unknown. (Wackerly §8.7)
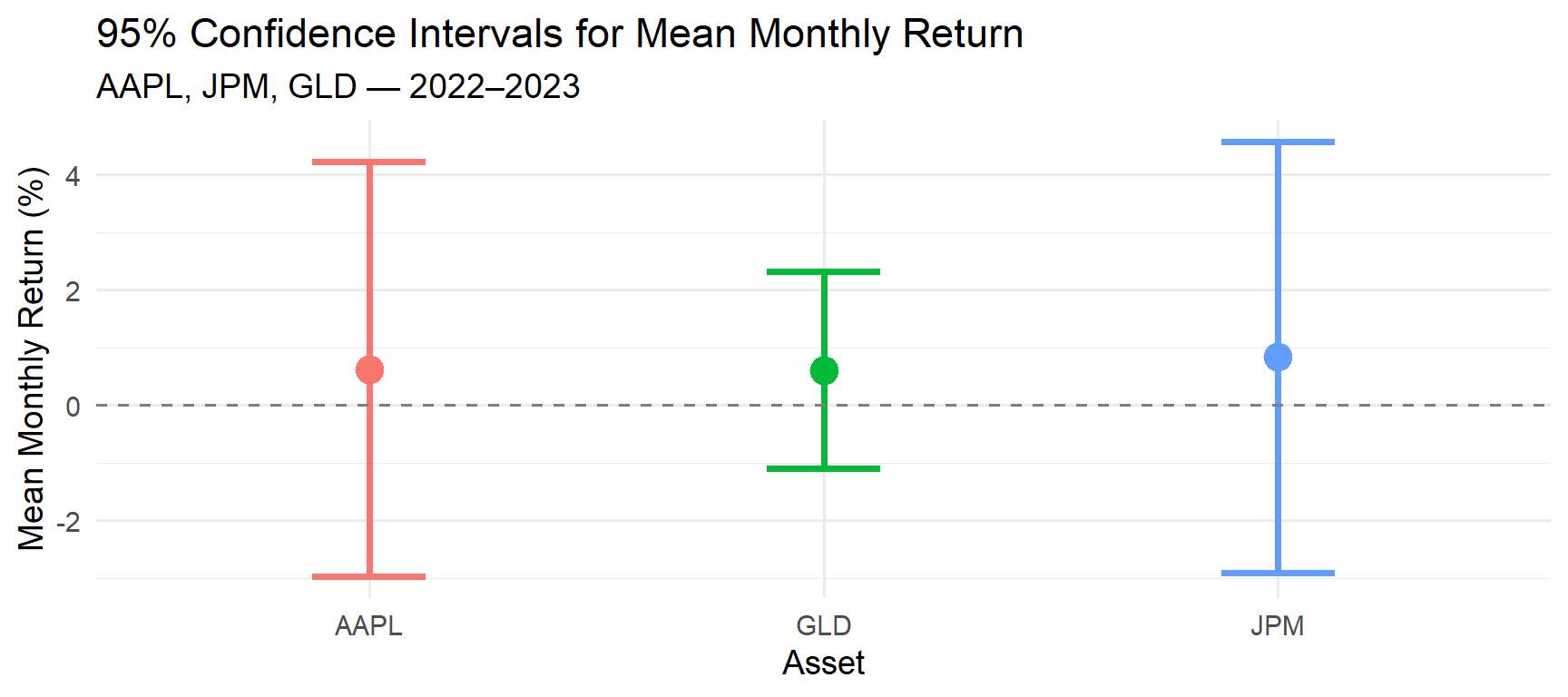
Problem 3 (Two-Sample \(t\)): Fund A: \(n_1 = 12\), \(\bar{y}_1 = 8.4\%\), \(s_1 = 3.1\%\). Fund B: \(n_2 = 10\), \(\bar{y}_2 = 6.9\%\), \(s_2 = 2.8\%\). Assuming equal variances and normality, construct a 95% CI for \(\mu_A - \mu_B\). Can you conclude Fund A outperforms Fund B? (Wackerly Ex. 8.85)
Problem 4 (CI for \(\sigma^2\)): A quality control analyst measures quarterly return variance for a risk model. From \(n = 15\) observations, \(s^2 = 5.76\) (%²). Construct a 95% CI for \(\sigma^2\) and interpret in terms of annualized volatility. (Wackerly §8.9)